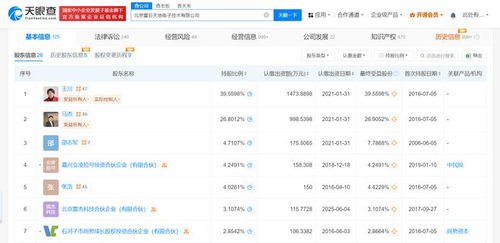
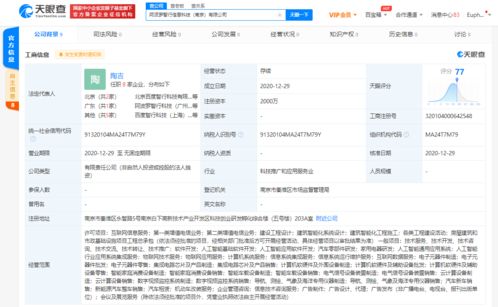
微軟發布了一項突破性的人工智能技術,僅需3秒鐘的音頻樣本即可高精度模擬任何人的聲音。這一技術的問世,不僅標志著語音合成領域的重大飛躍,也為人工智能應用軟件的開發打開了全新的可能性。
在傳統的語音合成系統中,通常需要采集數小時的目標人聲數據,并經過復雜的模型訓練才能實現聲音模擬。而微軟的新AI技術基于先進的深度學習框架,通過對短樣本的深度特征提取與模式匹配,實現了前所未有的高效性與準確性。研究人員表示,該技術能夠捕捉聲音的獨特韻律、音色和情感特征,生成的語音幾乎與原始聲音無法區分。
這項技術的應用前景極為廣闊。在娛樂產業中,它可以用于為游戲角色、虛擬偶像或動畫人物賦予更自然的人聲;在教育領域,能夠幫助語言學習者模仿母語者的發音;在無障礙服務方面,可為失聲患者重建個人化語音;甚至在影視后期制作中,也能高效完成配音與音頻修復工作。
這項技術也引發了關于聲音安全和倫理的討論。微軟表示已意識到潛在風險,正在開發相應的水印技術和檢測工具,以防止惡意使用。公司強調該技術將遵循嚴格的倫理準則,確保在獲得明確授權的前提下使用。
從軟件開發的角度來看,這項技術為AI應用開發者提供了強大的新工具。開發者可以通過微軟提供的API接口,將這一語音合成能力集成到各種應用中,從而創造出更具互動性和個性化的用戶體驗。預計未來幾個月內,微軟將向部分合作伙伴開放測試接口,逐步推進商業化應用。
隨著人工智能技術的不斷成熟,聲音模擬只是AI賦能軟件開發的一個縮影。從計算機視覺到自然語言處理,從語音識別到生成式AI,這些技術正在共同推動著軟件產業向更智能、更人性化的方向發展。微軟的這項創新再次證明,AI技術正以前所未有的速度改變著我們與數字世界交互的方式。